Friday, March 30, 2007
hand wash only?
Monday, March 12, 2007
Not the Dalai Lama
There is an urban legend of sorts circulating through the healing arts profession regarding a CD, often distributed with a note attached claiming that the CD contains a healing chant by the Dalai Lama, which he initially refused to allow a recording of, but later agreed to on the stipulation that the recording never be sold, only given. The CD contains what sounds like a somewhat poor cassette recording that has been transferred to CD. There are numerous tape dropouts and distortions, with one channel louder than the other (a dead giveaway of some transfer to/from cassette and that it was played back on a different unit than it was recorded on, or at least with a slightly different head bias).
I did a little digging on the Internet when I went to go look for this recording, having had a desire to do what I could to clean up the sound as best I could in Sound Forge, at least to give it decent equalization and balance and to try to clean up some of the clipping (it was at some point in its life recorded such that the levels were too high and the audio saturated the recording device's inputs).
Through this digging I learned that the recording was actually supposedly of a Dutch man named Hein Braat, on a CD for commercial sale called "The Gayatri Mantra". The track selection in question that starts on the bootleg CD is called "Mrityonjaya Mantra". The letter accompanying the bootleg calls the disc the "Maha Mrityunjaya" Mantra.
To me the sample on the Isabella Catalog site sounded strikingly similar to the recording on the bootleg disc. I reported this fact to my Hendrickson Method of Orthopedic Massage class.
One response I got was that although the chant was the same, the voice sounded different. And that is actually true. It does sound different. The reason it sounds different is that it was recorded on one cassette player and played back on another one when it was transferred to CD. Cassette players are notorious for having poor accuracy in their playback speeds. They're meant to be 1.875 inches per second, but there are all kinds of tiny variances.
To see if it is indeed the same voice, I loaded the CD into Sony Media Software's Sound Forge, a professional-quality sound editing tool. Figuring I needed to correct a tape speed problem, I applied a tiny amount of pitch shift, without compensating for speed. I sped up the recording by 76.0 cents, which is 76% of one semitone (and there are 12 semitones to an octave). This is roughly equivalent to correcting for a cassette tape running at about 1.75 inches per second, or about 6% too slowly. I did this pitch shift by ear. For anyone who knows me well, that's about as good as you'll get. (I can't visit karaoke bars or watch American Idol because anything that's even slightly off-key hurts my ears.)
Next I used the Sound Forge spectrum analysis tool on one "Om" from each source. They did not come from the same "om" in the same place in the chant (rather, I just used the first one I came to in each) but each is the same pitch. I turned up the accuracy to a FFT (fast fourier transform) size of 32768, which is certainly adequate for a single voice in the 0-22050 Hz range. Here are the two graphs for comparison. First the bootleg CD:
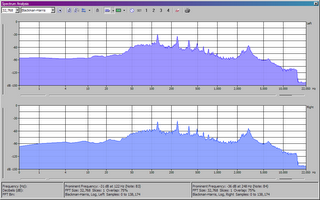
Next, the sample of the professional CD from the online store:
Keep in mind that the bootleg CD suffers from heavy dropouts and distortion from spending some portion of its life on cassette. But notice the peaks in the singer's voice. These harmonics are different for every person's voice. We would certainly expect to see peaks for each note that was actually being sung, but the subtle characteristics are the most interesting things. Look, for example, at the peaks that appear between 1,000 and 2,000 Hz. No note in this frequency range is being sung in the "Om" syllable, so these are pure vocal harmonics, characteristic of the singer's voice.
In the bootleg CD, we find peaks at around 1000, 1104, 1245, 1344, 1498, 1600, 1745 and 1863 Hz. On the sample from the Braat CD, we find peaks at 1001, 1046, 1104, 1232, 1344, 1498, 1600, 1764, 1863 and 1925 Hz. It isn't particularly surprising that we would find more peaks from a higher quality source. The fact that so many of these vocal harmonic frequencies match exactly (or extremely nearly) and even follow a nearly identical amplitude curve strongly suggests that it is the same voice in both recordings.
Much as I'd love for the Dalai Lama story to be true, I'm convinced that it is false.
I did a little digging on the Internet when I went to go look for this recording, having had a desire to do what I could to clean up the sound as best I could in Sound Forge, at least to give it decent equalization and balance and to try to clean up some of the clipping (it was at some point in its life recorded such that the levels were too high and the audio saturated the recording device's inputs).
Through this digging I learned that the recording was actually supposedly of a Dutch man named Hein Braat, on a CD for commercial sale called "The Gayatri Mantra". The track selection in question that starts on the bootleg CD is called "Mrityonjaya Mantra". The letter accompanying the bootleg calls the disc the "Maha Mrityunjaya" Mantra.
To me the sample on the Isabella Catalog site sounded strikingly similar to the recording on the bootleg disc. I reported this fact to my Hendrickson Method of Orthopedic Massage class.
One response I got was that although the chant was the same, the voice sounded different. And that is actually true. It does sound different. The reason it sounds different is that it was recorded on one cassette player and played back on another one when it was transferred to CD. Cassette players are notorious for having poor accuracy in their playback speeds. They're meant to be 1.875 inches per second, but there are all kinds of tiny variances.
To see if it is indeed the same voice, I loaded the CD into Sony Media Software's Sound Forge, a professional-quality sound editing tool. Figuring I needed to correct a tape speed problem, I applied a tiny amount of pitch shift, without compensating for speed. I sped up the recording by 76.0 cents, which is 76% of one semitone (and there are 12 semitones to an octave). This is roughly equivalent to correcting for a cassette tape running at about 1.75 inches per second, or about 6% too slowly. I did this pitch shift by ear. For anyone who knows me well, that's about as good as you'll get. (I can't visit karaoke bars or watch American Idol because anything that's even slightly off-key hurts my ears.)
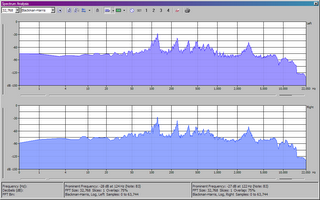
Next I used the Sound Forge spectrum analysis tool on one "Om" from each source. They did not come from the same "om" in the same place in the chant (rather, I just used the first one I came to in each) but each is the same pitch. I turned up the accuracy to a FFT (fast fourier transform) size of 32768, which is certainly adequate for a single voice in the 0-22050 Hz range. Here are the two graphs for comparison. First the bootleg CD:

Next, the sample of the professional CD from the online store:
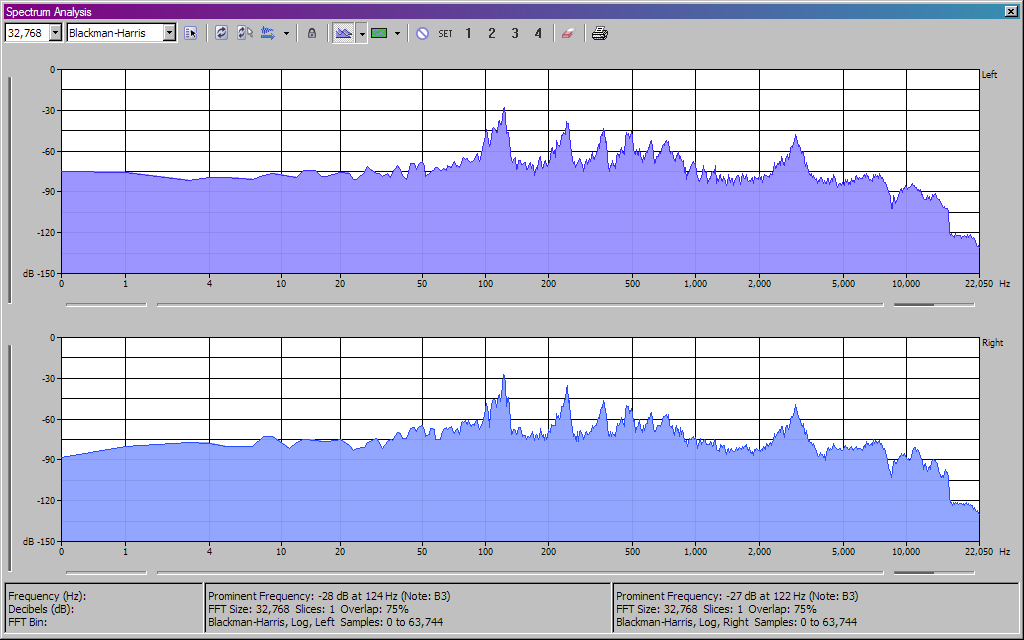
Keep in mind that the bootleg CD suffers from heavy dropouts and distortion from spending some portion of its life on cassette. But notice the peaks in the singer's voice. These harmonics are different for every person's voice. We would certainly expect to see peaks for each note that was actually being sung, but the subtle characteristics are the most interesting things. Look, for example, at the peaks that appear between 1,000 and 2,000 Hz. No note in this frequency range is being sung in the "Om" syllable, so these are pure vocal harmonics, characteristic of the singer's voice.
In the bootleg CD, we find peaks at around 1000, 1104, 1245, 1344, 1498, 1600, 1745 and 1863 Hz. On the sample from the Braat CD, we find peaks at 1001, 1046, 1104, 1232, 1344, 1498, 1600, 1764, 1863 and 1925 Hz. It isn't particularly surprising that we would find more peaks from a higher quality source. The fact that so many of these vocal harmonic frequencies match exactly (or extremely nearly) and even follow a nearly identical amplitude curve strongly suggests that it is the same voice in both recordings.
Much as I'd love for the Dalai Lama story to be true, I'm convinced that it is false.
Labels: chain letter, dalai lama, healing chant, urban legend
Sunday, March 11, 2007
JPA + J2SE Servlet Containers = Impossible
Well, somewhat impossible depending on what you need to do.
If you need dynamic weaving of your classes at runtime, give up. It won't work, not with a J2SE servlet container.
The problem seems to be that the javaagent (for both OpenJPA and for Toplink Essentials) is incapable of coping with classes that are loaded by a different classloader. If you manage to get your javaagent JVM argument to work (which will require annoying experiments with quotation marks and adding stuff to your classpath), then all of your Entity classes will fail to load because the agent can't find them. They don't exist as far is it is concerned, because they are loaded by a different classloader.
So if you want to use lazy loading of 1:1 fields with a J2SE container, you must either do static weaving or give up hope. Your other option is to use a full-blown J2EE container in all its bloated glory.
Screw this. I'm going to bed.
If you need dynamic weaving of your classes at runtime, give up. It won't work, not with a J2SE servlet container.
The problem seems to be that the javaagent (for both OpenJPA and for Toplink Essentials) is incapable of coping with classes that are loaded by a different classloader. If you manage to get your javaagent JVM argument to work (which will require annoying experiments with quotation marks and adding stuff to your classpath), then all of your Entity classes will fail to load because the agent can't find them. They don't exist as far is it is concerned, because they are loaded by a different classloader.
So if you want to use lazy loading of 1:1 fields with a J2SE container, you must either do static weaving or give up hope. Your other option is to use a full-blown J2EE container in all its bloated glory.
Screw this. I'm going to bed.
Labels: j2ee, javaagent, JPA, servlet, software, weaving
Tuesday, March 06, 2007
More Adventures with JPA
Since Toplink isn't up to the task, tonight I decided to get all my tests working with OpenJPA. Normally this should be simply a matter of plugging in a different implementation and everything would work swimmingly. Ah, but we all know it's never that easy.
The trouble is that the JPA spec, being an early revision, leaves a lot of things up to the implementer. This includes all cache control. So it is actually fairly easy to find yourself relying upon the caching semantics of a particular provider, and you may find that unit tests that work correctly with one provider begin to fail when you plug in another one.
A classic example of this is the simple 1:Many relationship. Say you have two objects called Root and Message. One Root contains many Messages. Now you want to perform these operations:
Now you may already see the obvious problem with this chain of events, but pretend for a moment that you don't.
In Toplink, this works. The "Get messages from root" step initiates a query to the database to get all of the Message objects associated to the root (lazy loading).
In OpenJPA, this fails. OpenJPA has been tracking the Root object in its cache, and it already knows that the Root object has no message objects. So it performs no query, and the list of Messages is empty.
Of course had I adhered to a best practice of dealing with ORM, this would never have happened. When there is a 1:Many relationship, one should always perform operations on the owning side of the relationship. That means you don't set the root ID from the Message; instead, you add the Message to the list of children that belong to the Root.
Complicating matters, that strategy tends to work in Toplink, but OpenJPA will not set up the owned side of the relationship (ie, the root reference). So you actually have to do both: set the root reference in the Message, and add the Message to the Root's children list. JPA implementations will automatically persist the owned side of the relationship at least, if you set the right value(s) for
The safest thing is to maintain both sides of the relationship, though this isn't a particularly intuitive thing to have to do.
And what night would be complete without opening a bug report? Tonight it's OPENJPA-164. I kept getting an exception from OpenJPA tonight that was a rethrowing of a PostgreSQL exception that "f" was not valid data for the BigDecimal type when reading in an instance of class Article. And that was all the information I had to go on. It later turned out that the culprit was the way I had previously mapped ArticleMessageRoot, which had a field called "posting_permitted" mapped as a long instead of a boolean. This worked with Toplink, because Toplink read the field as a long, and PostgreSQL evidently had a conversion that was workable for a boolean to a long, but not a BigDecimal. The good news is that the problem has been caught- it really should have been mapped as a boolean. The bad news is that OpenJPA gave me absolutely nothing to go on for a fairly commonplace mapping error, even with logging cranked all the way up to TRACE.
All the service unit tests are passing now, so it's progress.
The trouble is that the JPA spec, being an early revision, leaves a lot of things up to the implementer. This includes all cache control. So it is actually fairly easy to find yourself relying upon the caching semantics of a particular provider, and you may find that unit tests that work correctly with one provider begin to fail when you plug in another one.
A classic example of this is the simple 1:Many relationship. Say you have two objects called Root and Message. One Root contains many Messages. Now you want to perform these operations:
- Create Root
- Create Message that refers to the Root
- Read Root
- Get messages from Root
Now you may already see the obvious problem with this chain of events, but pretend for a moment that you don't.
In Toplink, this works. The "Get messages from root" step initiates a query to the database to get all of the Message objects associated to the root (lazy loading).
In OpenJPA, this fails. OpenJPA has been tracking the Root object in its cache, and it already knows that the Root object has no message objects. So it performs no query, and the list of Messages is empty.
Of course had I adhered to a best practice of dealing with ORM, this would never have happened. When there is a 1:Many relationship, one should always perform operations on the owning side of the relationship. That means you don't set the root ID from the Message; instead, you add the Message to the list of children that belong to the Root.
Complicating matters, that strategy tends to work in Toplink, but OpenJPA will not set up the owned side of the relationship (ie, the root reference). So you actually have to do both: set the root reference in the Message, and add the Message to the Root's children list. JPA implementations will automatically persist the owned side of the relationship at least, if you set the right value(s) for
cascade in the @OneToMany annotation (to CascadeType.PERSIST or CascadeType.ALL). (OpenJPA has its own annotation, @InverseLogical, to indicate that a field should be maintained bidirectionally.) Otherwise you have to explicitly persist both objects.The safest thing is to maintain both sides of the relationship, though this isn't a particularly intuitive thing to have to do.
And what night would be complete without opening a bug report? Tonight it's OPENJPA-164. I kept getting an exception from OpenJPA tonight that was a rethrowing of a PostgreSQL exception that "f" was not valid data for the BigDecimal type when reading in an instance of class Article. And that was all the information I had to go on. It later turned out that the culprit was the way I had previously mapped ArticleMessageRoot, which had a field called "posting_permitted" mapped as a long instead of a boolean. This worked with Toplink, because Toplink read the field as a long, and PostgreSQL evidently had a conversion that was workable for a boolean to a long, but not a BigDecimal. The good news is that the problem has been caught- it really should have been mapped as a boolean. The bad news is that OpenJPA gave me absolutely nothing to go on for a fairly commonplace mapping error, even with logging cranked all the way up to TRACE.
All the service unit tests are passing now, so it's progress.
Labels: software
Toplink Essentials: Not Ready for Prime Time
I really really like the Toplink commercial product. I think it's tremendously powerful, flexible, well-supported, and rock-solid. It does exactly what it is supposed to do, every time.
I wish I could say the same for Toplink Essentials. It feels like the open source branching was done as a rush-job, leaving large portions of the necessary code and tooling undone. My simple test case to take advantage of "weaving" (bytecode instrumentation) fails. My attempt to make the instrumentation work using static weaving (post-compile and pre-run) also fails, but in a different way. These are not elaborate test cases. My code isn't terribly complex yet, and my schema is fairly straightforward. Yet Toplink falls down and goes splat. Some of their tools can't even handle spaces in the pathname.
For now I'll keep using OpenJPA until the Glassfish people can make Toplink Essentials stop sucking so damn much. OpenJPA is a bit more pedantic anyway, and that's a good thing. My code should end up tighter as a result.
Much of this JPA stuff just isn't ready for the real world yet, though it's been a final spec since last May and a proposed final draft since December of 2005. They don't even have support for @OneToOne in Eclipse WTP 2.0 yet, and every edit to the persistence.xml file brings up some lame dialog box whining about a ConcurrentModificationException. Granted, it's just a milestone build. But this is the type of frustration one encounters when trying to use JPA.
And no, I'm not going to use sucky Hibernate and their dozens of goddamn dependencies, lack of integrated object caching, and mental-defective nerd community.
I wish I could say the same for Toplink Essentials. It feels like the open source branching was done as a rush-job, leaving large portions of the necessary code and tooling undone. My simple test case to take advantage of "weaving" (bytecode instrumentation) fails. My attempt to make the instrumentation work using static weaving (post-compile and pre-run) also fails, but in a different way. These are not elaborate test cases. My code isn't terribly complex yet, and my schema is fairly straightforward. Yet Toplink falls down and goes splat. Some of their tools can't even handle spaces in the pathname.
For now I'll keep using OpenJPA until the Glassfish people can make Toplink Essentials stop sucking so damn much. OpenJPA is a bit more pedantic anyway, and that's a good thing. My code should end up tighter as a result.
Much of this JPA stuff just isn't ready for the real world yet, though it's been a final spec since last May and a proposed final draft since December of 2005. They don't even have support for @OneToOne in Eclipse WTP 2.0 yet, and every edit to the persistence.xml file brings up some lame dialog box whining about a ConcurrentModificationException. Granted, it's just a milestone build. But this is the type of frustration one encounters when trying to use JPA.
And no, I'm not going to use sucky Hibernate and their dozens of goddamn dependencies, lack of integrated object caching, and mental-defective nerd community.
Labels: JPA, open JPA, software, toplink
Sunday, March 04, 2007
Open JPA Can't @OrderBy a Related Object's @Id
https://issues.apache.org/jira/browse/OPENJPA-162
I just can't win tonight.
UPDATE: it turns out that @OrderBy with no options means to order by the identity value of the related object, and this does work correctly in OpenJPA.
I just can't win tonight.
UPDATE: it turns out that @OrderBy with no options means to order by the identity value of the related object, and this does work correctly in OpenJPA.
Labels: open JPA, shitware, software
Toplink's Weaving is Broken
I'm reminded tonight of why I hate things that happen by "magic" in code. They are great when they're working correctly, but an impossible pain in the ass to debug when things go wrong. This is the primary reason why I dislike AOP; how do you debug something that isn't in your code? Toplink's "weaving" is very AOP-ish; it's effectively intercepting Java bytecode for setting the values for fields.
Or rather, it's not doing it very effectively, if I may overload usage of the word, because it's totally broken in a very simple and stupid way which even a primitive test case should reveal. It fails to correctly instrument put field operation for a field that has an associated Entity. In this case, that means that when I try to set my MessageRoot on my Message, I get this:
As you can probably imagine, I did not write a method called _toplink_setroot. The problem is, neither did Toplink, even though it should have.
Since the Toplink instrumentation code doesn't appear to do any logging of any kind, it is utterly impossible to debug this problem. I have exactly nothing at all to go on, other than the name of a method that doesn't exist, which Toplink should have supplied if it wanted to call it.
Much as I wanted to use Toplink for this project, this problem is a complete deal-breaker. What's particularly startling to me is that such a simple test case can fail without anyone noticing.
Next I guess I'll try BEA's Open JPA (Kodo) and see if they can manage to do proper lazy loading of a 1:1 relationship AND let me create that relationship too... since that's too much to ask of Toplink.
Or rather, it's not doing it very effectively, if I may overload usage of the word, because it's totally broken in a very simple and stupid way which even a primitive test case should reveal. It fails to correctly instrument put field operation for a field that has an associated Entity. In this case, that means that when I try to set my MessageRoot on my Message, I get this:
java.lang.NoSuchMethodError:
net.spatula.tally_ho.model.Message._toplink_setroot(Lnet/spatula/tally_ho/model/MessageRoot;)V
at net.spatula.tally_ho.model.Message.setRoot(Message.java:169)
As you can probably imagine, I did not write a method called _toplink_setroot. The problem is, neither did Toplink, even though it should have.
Since the Toplink instrumentation code doesn't appear to do any logging of any kind, it is utterly impossible to debug this problem. I have exactly nothing at all to go on, other than the name of a method that doesn't exist, which Toplink should have supplied if it wanted to call it.
Much as I wanted to use Toplink for this project, this problem is a complete deal-breaker. What's particularly startling to me is that such a simple test case can fail without anyone noticing.
Next I guess I'll try BEA's Open JPA (Kodo) and see if they can manage to do proper lazy loading of a 1:1 relationship AND let me create that relationship too... since that's too much to ask of Toplink.
Labels: AOP, kodo, NoSuchMethodError, open JPA, software, toplink, weaving
Saturday, March 03, 2007
Another picture of the new haircut

my new 'do
Optimizing the Message Tree with JPA
The trouble with recursive tree structures is that databases tend to give poor performance implementing them. Further, JPA doesn't really natively do trees (so far as I can tell). Fortunately, morons.org solved this problem a very long time ago. My solution was to associate each collection of messages with a single "root" (though it isn't a root in the true sense of the word) and with each other. If you happened to have "connect by" syntax with your database, you could take advantage of it by virtue of the parent_id column. If you didn't, you could always do a fairly quick pass through the full collection of messages you got off the single root. The latter is exactly what Tally Ho will be doing with JPA.
Key to making this work is denoting the 1:1 relationship to the parent as
When I first tried this with Glassfish Persistence (aka Toplink Essentials) it seemed to be ignoring my request to use FetchType.LAZY. As soon as the first object loaded, it loaded its parent. And the parent of that object. And so on, recursively. Toplink would issue one
It turns out that for proper behaviour you need to turn on something the Toplink folks call "weaving", which I suspect is actually just a fancy Oracle term for Java bytecode instrumentation. To do this, you add the property
Once I did this, Toplink would happily wait to fetch any parent objects until they were asked for. And by virtue of all parent/child relationships being collected inside the same "root", when you first ask for a parent, it has already been loaded in memory, so an additional trip to the database is not required.
The downside is that the "children" List on the Message won't get populated, and if you let JPA handle the population, it will again make a lot of trips to the database to figure out which children belong to which parent... it has no way of knowing my rule that all of the relationships among the children are contained within the confines of that one root.
Fortunately for the needs of Tally Ho, this problem is easily mitigated. We simply mark the
The only reason we can get away with this is that we never look at a collection of
It's a tiny bit hackish, but the performance improvement is tremendous, so it's worth it. Over the Internet, through my ssh tunnel to my server, 180 message objects were loaded and linked together correctly in about 650ms. I suspect this will improve substantially when the database is on the local host.
Key to making this work is denoting the 1:1 relationship to the parent as
fetch=FetchType.LAZY.When I first tried this with Glassfish Persistence (aka Toplink Essentials) it seemed to be ignoring my request to use FetchType.LAZY. As soon as the first object loaded, it loaded its parent. And the parent of that object. And so on, recursively. Toplink would issue one
SELECT statement for every single object in the database for the "root" in question. Obviously the performance of this strategy really sucked.It turns out that for proper behaviour you need to turn on something the Toplink folks call "weaving", which I suspect is actually just a fancy Oracle term for Java bytecode instrumentation. To do this, you add the property
toplink.weaving to persistence.xml and set its value to true. You must also add the JVM argument -javaagent:{path to libs}/toplink-essentials-agent.jar to your running configuration.Once I did this, Toplink would happily wait to fetch any parent objects until they were asked for. And by virtue of all parent/child relationships being collected inside the same "root", when you first ask for a parent, it has already been loaded in memory, so an additional trip to the database is not required.
The downside is that the "children" List on the Message won't get populated, and if you let JPA handle the population, it will again make a lot of trips to the database to figure out which children belong to which parent... it has no way of knowing my rule that all of the relationships among the children are contained within the confines of that one root.
Fortunately for the needs of Tally Ho, this problem is easily mitigated. We simply mark the
children List with @Transient to prevent JPA from trying to do anything with it at all. Then we pull this trick in MessageRoot:
public ListgetMessages() {
if (!messagesFixed) {
fixMessages();
}
return messages;
}
private void fixMessages() {
for (Message message : messages) {
if (message.getParent() != null) {
message.getParent().getChildren().add(message);
}
}
messagesFixed = true;
}
The only reason we can get away with this is that we never look at a collection of
Messages without getting it from the MessageRoot. In the cases where we do look at a single Message, we don't look at its children.It's a tiny bit hackish, but the performance improvement is tremendous, so it's worth it. Over the Internet, through my ssh tunnel to my server, 180 message objects were loaded and linked together correctly in about 650ms. I suspect this will improve substantially when the database is on the local host.
Labels: JPA, software, toplink, tree
Thursday, March 01, 2007
New Adventures in JPA with WTP 2.0M5
Tonight came the next logical step in the progression for tally-ho: migrate the old messages database to the new layout standards (and UTF-8 of course) and map the tables to entities using Dali.
The data migration was fairly easy to do, especially now that I've done it before with accounts and articles. Unfortunately when I went to map the new tables to Java classes, Dali pulled its disappearing act again. I don't recall whether I mentioned this here before, but Dali 0.5 has a tendency to just disappear from Eclipse for no apparent reason. It fails to load, silently of course. Why log an error, when you can silently fail?
Luckly, though, Dali has been integrated into the Eclipse Web Tools Project (WTP) version 2.0 and there's a reasonably functional version of it in 2.0M5. Of course the problem with milestone builds is that they tend to lack any documentation whatsoever, so you're kind of on your own.
This became immediately frustrating. When I opened the JPA perspective for the first time, I couldn't add a connection. The drivers list was empty. It turns out you have to first populate a connection via WTP from the Window/Properties/Connectivity/Driver Definitions menu. It was easy to add a definition to connect to my PostgreSQL 8.1 database.
(At some point during this process, there was a magnitude 4.2 earthquake about 30 miles away on the Calaveras fault that shook the house and made a good loud noise. It was a little mild shake followed by one nice big jolt and then some rolling. All told it lasted maybe 5 seconds and was probably the most startling jolt I've felt since I've lived here, with the exception of the magnitude 6.5 earthquake near Paso Robles on December 22, 2003 that caused the lights in my office in San Jose to sway and nearly sent me scrambling under my desk. That time I had about 30 seconds of warning from my coworker in Salinas who I was talking to on the phone at the time.)
(As a side note, I got tired of poking holes in my host machine's firewall, adding the IP to PostgreSQL's allow pg_hba.conf and reloading PostgreSQL every time my dynamic IP changed at home, so I did the most reasonable thing: I added an SSH tunnel from my local machine's loopback to my remote machine's loopback on port 5432. Now I just connect to localhost for PostgreSQL, and it magically works. Using the loopback address on both ends mitigates potential security problems from creating such a tunnel.)
Finally I was able to add a database, but nothing worked with JPA. This is apparently because the necessary settings and natures defined for JPA with earlier versions of Dali are outdated. To make matters worse, they did not create a context or other menu (yet) to add JPA to the current project as they had with Dali 0.5. So I did what any impatient geek would do: I created a new JPA project, and then manually copied the missing natures in .project and missing files in .settings to my existing project. This seems to have done the trick.
The next hurdle is that the Java Persistence/Generate Entities... context menu is broken. First it was popping up a dialog box asking for the connection and schema to use. I could select my connection, but the drop down for schemas was empty. Entering the schema name manually was fruitless. The Next and Finish buttons remained disabled.
So then, having experienced weirdness related to missing configuration before, I went on the hunt again. This time I found the JPA settings in the project properties. Here I could select a connection, so I did. While this did change the behaviour of Generate Entities, it was for the worse: now the menu does nothing. Silent failure. I have reported the problem on the Eclipse site and asked for advice, but for now this has me stuck. It's time for bed anyway.
The data migration was fairly easy to do, especially now that I've done it before with accounts and articles. Unfortunately when I went to map the new tables to Java classes, Dali pulled its disappearing act again. I don't recall whether I mentioned this here before, but Dali 0.5 has a tendency to just disappear from Eclipse for no apparent reason. It fails to load, silently of course. Why log an error, when you can silently fail?
Luckly, though, Dali has been integrated into the Eclipse Web Tools Project (WTP) version 2.0 and there's a reasonably functional version of it in 2.0M5. Of course the problem with milestone builds is that they tend to lack any documentation whatsoever, so you're kind of on your own.
This became immediately frustrating. When I opened the JPA perspective for the first time, I couldn't add a connection. The drivers list was empty. It turns out you have to first populate a connection via WTP from the Window/Properties/Connectivity/Driver Definitions menu. It was easy to add a definition to connect to my PostgreSQL 8.1 database.
(At some point during this process, there was a magnitude 4.2 earthquake about 30 miles away on the Calaveras fault that shook the house and made a good loud noise. It was a little mild shake followed by one nice big jolt and then some rolling. All told it lasted maybe 5 seconds and was probably the most startling jolt I've felt since I've lived here, with the exception of the magnitude 6.5 earthquake near Paso Robles on December 22, 2003 that caused the lights in my office in San Jose to sway and nearly sent me scrambling under my desk. That time I had about 30 seconds of warning from my coworker in Salinas who I was talking to on the phone at the time.)
(As a side note, I got tired of poking holes in my host machine's firewall, adding the IP to PostgreSQL's allow pg_hba.conf and reloading PostgreSQL every time my dynamic IP changed at home, so I did the most reasonable thing: I added an SSH tunnel from my local machine's loopback to my remote machine's loopback on port 5432. Now I just connect to localhost for PostgreSQL, and it magically works. Using the loopback address on both ends mitigates potential security problems from creating such a tunnel.)
Finally I was able to add a database, but nothing worked with JPA. This is apparently because the necessary settings and natures defined for JPA with earlier versions of Dali are outdated. To make matters worse, they did not create a context or other menu (yet) to add JPA to the current project as they had with Dali 0.5. So I did what any impatient geek would do: I created a new JPA project, and then manually copied the missing natures in .project and missing files in .settings to my existing project. This seems to have done the trick.
The next hurdle is that the Java Persistence/Generate Entities... context menu is broken. First it was popping up a dialog box asking for the connection and schema to use. I could select my connection, but the drop down for schemas was empty. Entering the schema name manually was fruitless. The Next and Finish buttons remained disabled.
So then, having experienced weirdness related to missing configuration before, I went on the hunt again. This time I found the JPA settings in the project properties. Here I could select a connection, so I did. While this did change the behaviour of Generate Entities, it was for the worse: now the menu does nothing. Silent failure. I have reported the problem on the Eclipse site and asked for advice, but for now this has me stuck. It's time for bed anyway.
Labels: software
![]()
Subscribe to Posts [Atom]
